|
Yinji ShenTu I am currently a Ph.D. student in ZJU3DV since 2024, advised by Xiaowei Zhou and Wei Hua in Zhejiang University. I used to work as a research assistant at the group. Before join ZJU3DV, I received my B.S. degree from Dalian University of Technology and MSc degree from The University of Hong Kong. I used to work as an intern algorithm researcher at Hikvision focus on improve the quality of CCTV. My research interests are in computer vision and graphics, especially with deep learning. My vision is to enable computers to better understand and simulate the real world, which corresponds to vision -- graphics tasks. In the first two years, I majorly explored the editiability of volumetric video reconstructed, especially reconstructed fron monocular video. Email / Google Scholar / Github / X |

|
ResearchMy research interests are mentioned above. Representative papers are highlighted. |

|
Dyn-E: Local Appearance Editing of Dynamic Neural Radiance Fields
Shangzhan Zhang, Yinji ShenTu, Mingyue Xu, Sida Peng, Shuai Qing, Tianrun Chen, Kaicheng Yu, Hujun Bao, Xiaowei Zhou Chinagraph, 2024 (Best Paper Award!) project page / video / paper DRAW: solution to dynamic appearance edit with only single-image input for volumetric video. |

|
DS-Hybrid GS: auto-reconstruction and decomposition from monocular video
under review paper REMOVE: automatic reconstruction and decomposition for monocular videos |
|
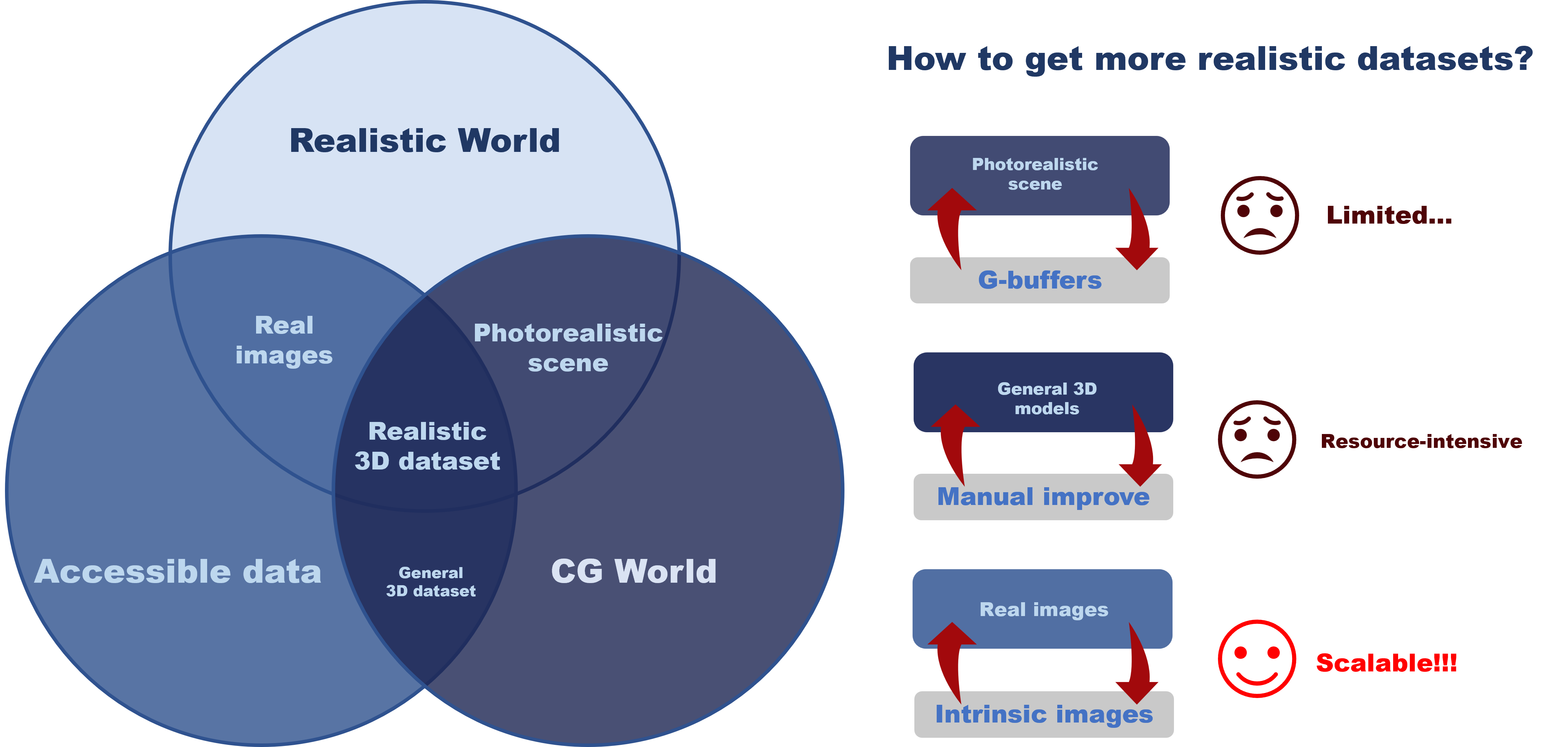
Diffusion-based Photo-realistic Rendering with Scalable Synthetic-real Paired Data
under review paper INSERT: Photo-realistic rendering method base diffusion model with Scalable Synthetic-real paired data. |
|
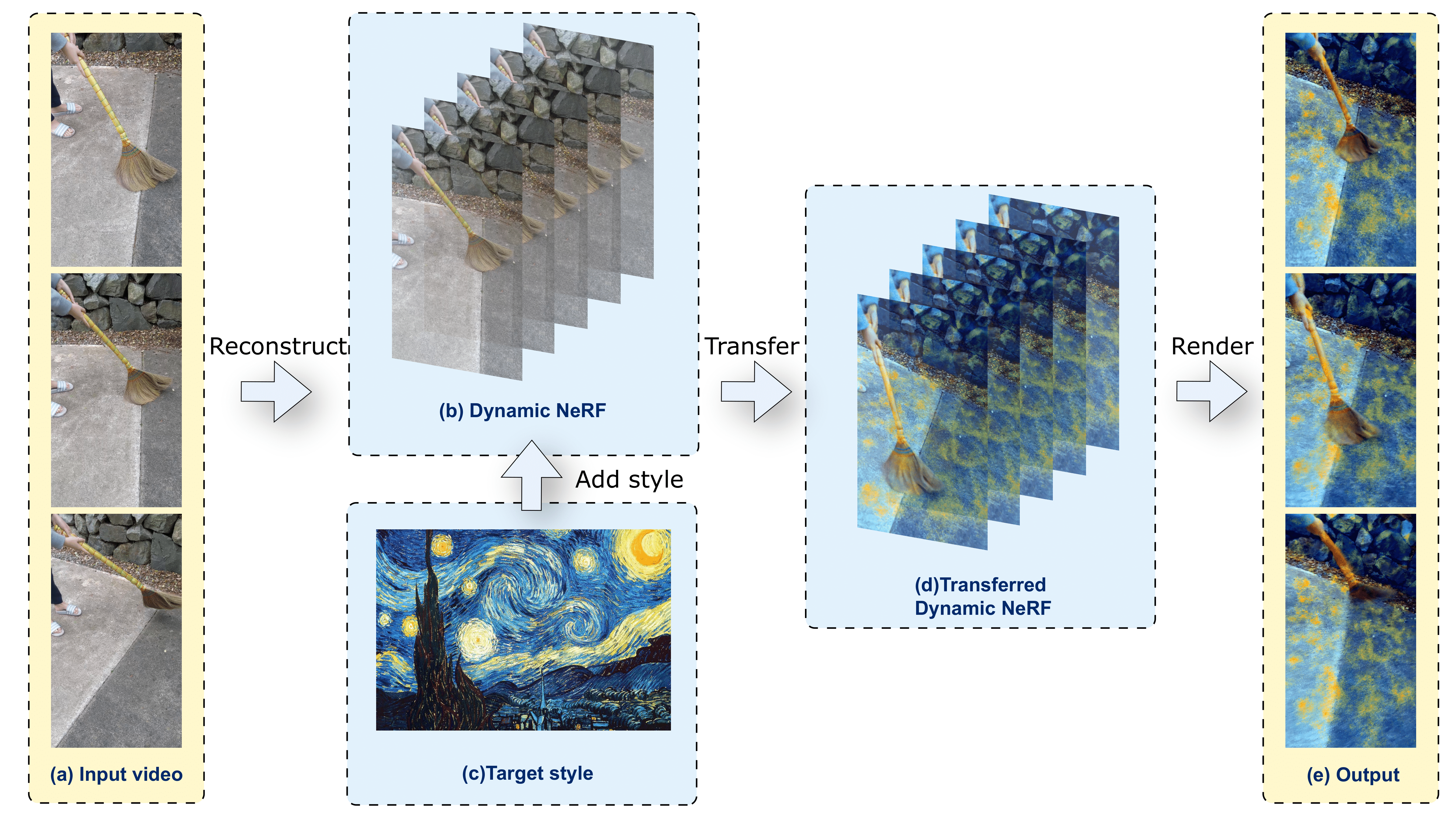
Video style transfer via implicit 4D representation
Yinji ShenTu, Tianrun Chen, Bojian Wu paper STYLE: Volumetric video stylization |
{kind=link}
|
Thanks Jon Barron for sharing this website's template source code. |